
🌈 I am Xuyang Liu (刘旭洋), an incoming PhD student at PolyU ![]() , where I will join the VC Lab
, where I will join the VC Lab ![]() under the supervision of Chair Prof. Lei Zhang (IEEE Fellow). I am also currently working as a research intern at OPPO Research Institute
under the supervision of Chair Prof. Lei Zhang (IEEE Fellow). I am also currently working as a research intern at OPPO Research Institute ![]() . Previously, I earned my M.S. from Sichuan University
. Previously, I earned my M.S. from Sichuan University ![]() and spent a wonderful year interning at Alibaba Group
and spent a wonderful year interning at Alibaba Group ![]() and Ant Group
and Ant Group ![]() . I am fortunate to work closely with Dr. Siteng Huang and Prof. Linfeng Zhang.
. I am fortunate to work closely with Dr. Siteng Huang and Prof. Linfeng Zhang.
📌 My research centers on Efficient Multimodal Large Language Models (MLLMs), including:
🖼️ Image Understanding
High-resolution understanding via context compression and fast decoding, including GlobalCom2[AAAI’26], V2Drop[CVPR’26], FiCoCo[AAAI’26], and MixKV[ICLR’26].
🎬 Video Understanding
Long/audio-video, and streaming reasoning via efficient encoding and compression, including VidCom2[EMNLP’25], STC[CVPR’26], V-CAST, and OmniSIFT[ICML’26].
🎨 Content Generation
Lightweight and efficient AIGC via feature caching, pruning and fast decoding, including ToCa[ICLR’25], Flash-Unified[CVPR’26 Findings], and STDec.
⚙️ Efficiency Toolbox
Efficient transfer/fine-tuning and benchmarking for downstream task adaptation, including M2IST[TCSVT’25], V-PETL[NeurIPS’24] and AutoGnothi[ICLR’25].
📢 If you find these directions interesting, feel free to reach out via email: liuxuyang@stu.scu.edu.cn.
🔥 News
- 2026.07.10🎊🎊 Two papers about efficient large audio language models (LALMs) have been accepted by MM 2026, including task-adaptive audio token pruning via HeadRouter and KV cache eviction via AudioKV.
- 2026.06.26🎓🎓 I successfully received my M.S. degree from Sichuan University, and my Master's thesis was selected as an Outstanding Master’s Thesis (top 2%).
- 2026.04.30🎊🎊 One paper OmniSIFT about modality-asymmetric token compression for efficient OmniLLMs has been accepted by ICML 2026! Congratulations to all collaborators!
- 2026.03.31
- 2026.02.21🎊🎊 Four papers have been accepted by CVPR 2026, including token compression for VLMs via V2Drop, efficient streaming video understanding via STC, and token compression for autonomous driving via Prune2Drive to the main conference, and Flash-Unified to the findings!
- 2026.01.26
- 2025.11.08🎊🎊 Three papers have been accepted by AAAI 2026, including two LVLM acceleration methods GlobalCom2 and FiCoCo, and a RL-based GUI grounding training framework GUI-G2!
- 2025.08.21
- 2025.05.27🙌🙌 We release a new paper, pointing to shifting AI efficiency from model-centric to data-centric compression. Project is available! Our paper is honored to be the #2 Paper of the day!
- 2025.03.11🎊🎊 One first author paper (M2IST) about parameter-, memory-, and time-efficient fine-tuning for referring expression comprehension has been accepted by IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)!
- 2025.02.22🎊🎊 Two papers (ToCa and AutoGnothi) have been accepted by ICLR 2025! Congratulations to all collaborators!
- 2024.09.26🎊🎊 One co-first author paper (V-PETL) about unified visual parameter-efficient transfer learning benchmark has been accepted by NeurIPS 2024!
📝 Publications
Full publications are on my Google Scholar profile. *: Equal contribution. †: Project leader.
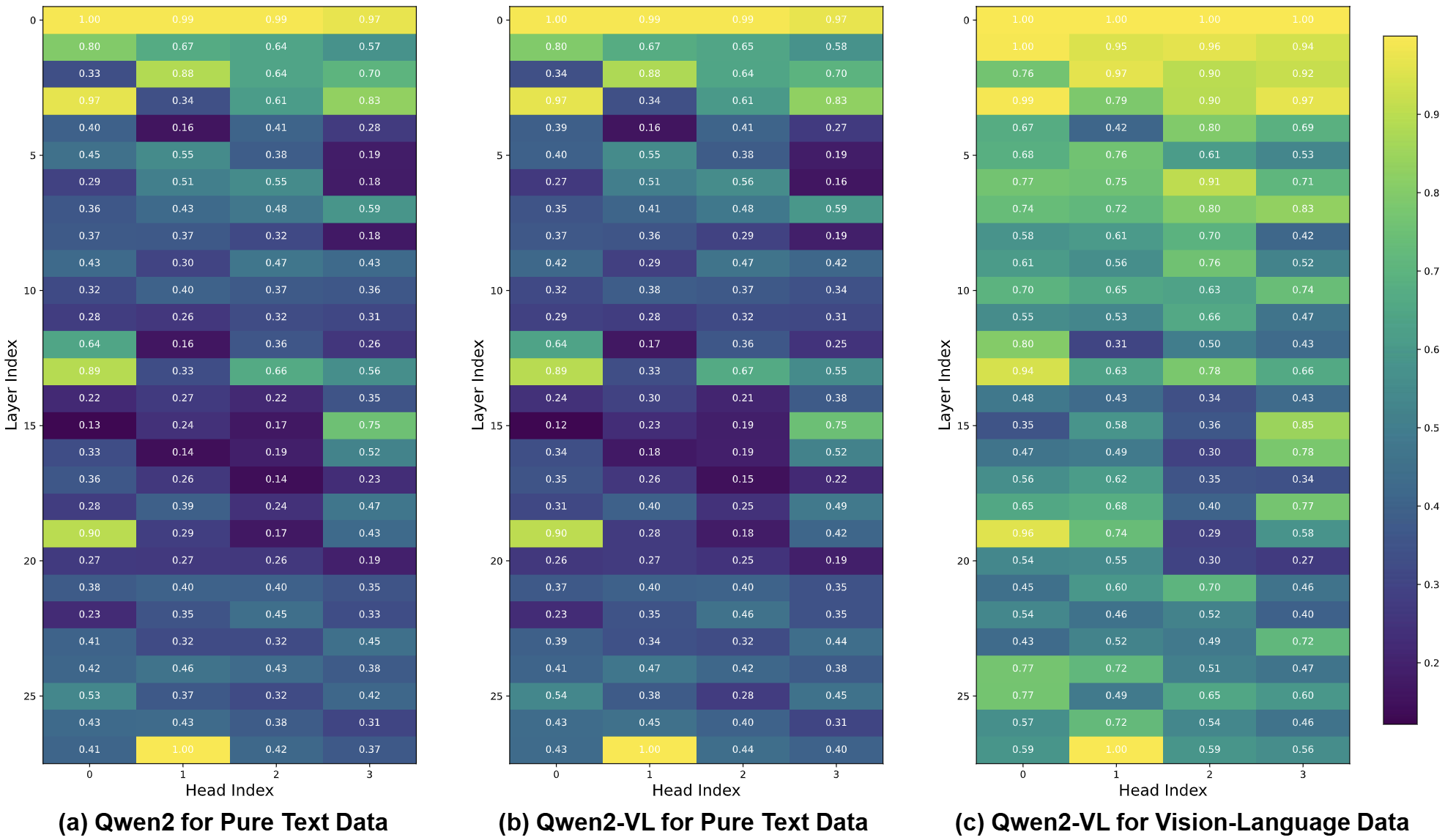
Xuyang Liu*, Xiyan Gui*, Yuchao Zhang, Linfeng Zhang
- Model Capability: LLaVA, Qwen-VL, InternVL, Llama, Mistral.
- Seamless Integration: SnapKV, AdaKV, SparseMM.
- Strong Performance: +5.1% gain across 5 tasks, no speed/memory cost.
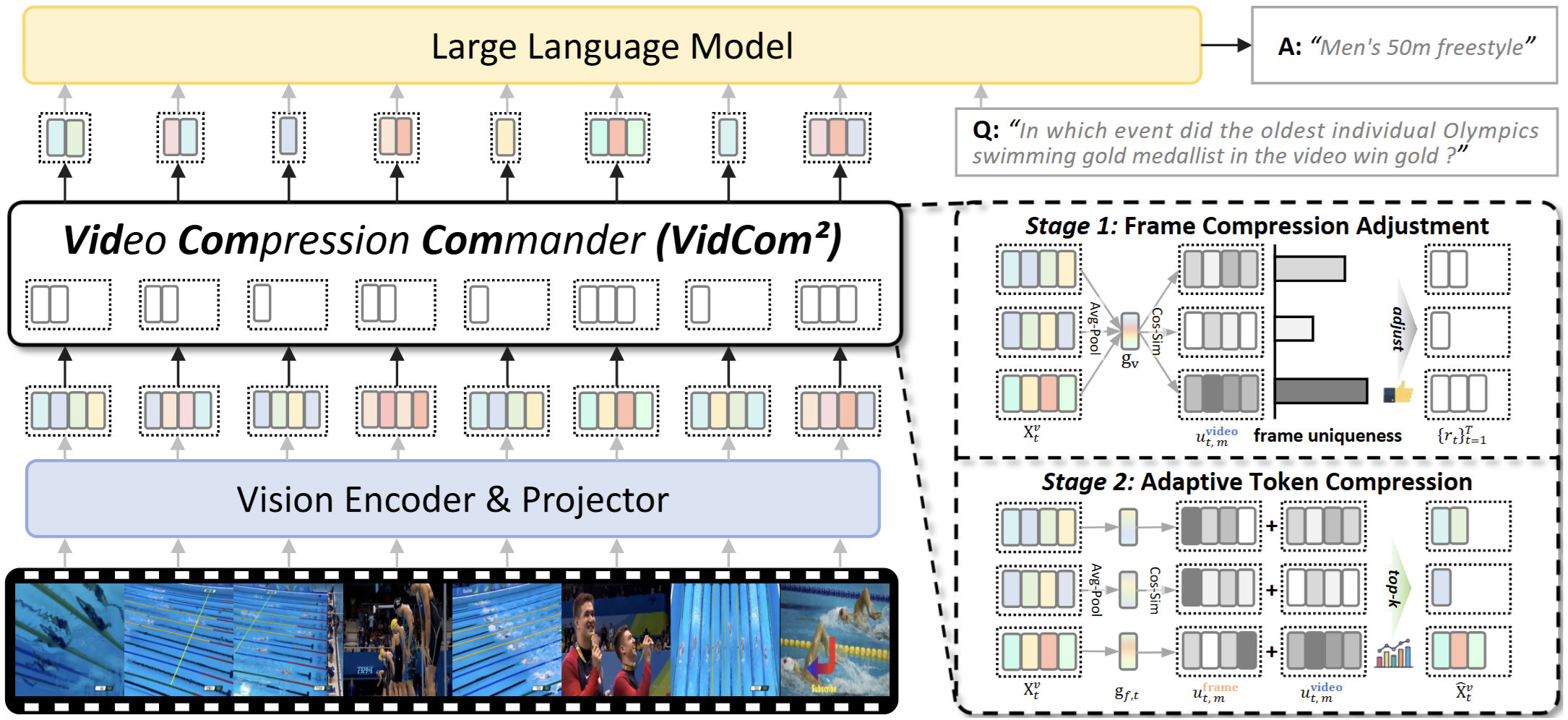
Video Compression Commander: Plug-and-Play Inference Acceleration for Video Large Language Models
Xuyang Liu*, Yiyu Wang*, Junpeng Ma, Linfeng Zhang
- Model Capability: LLaVA, Qwen-VL, Qwen-Omni.
- Token Compression: Only 25% tokens, 99.6% performance.
- Fast Inference: -70.8% generation time, -43.0% latency.
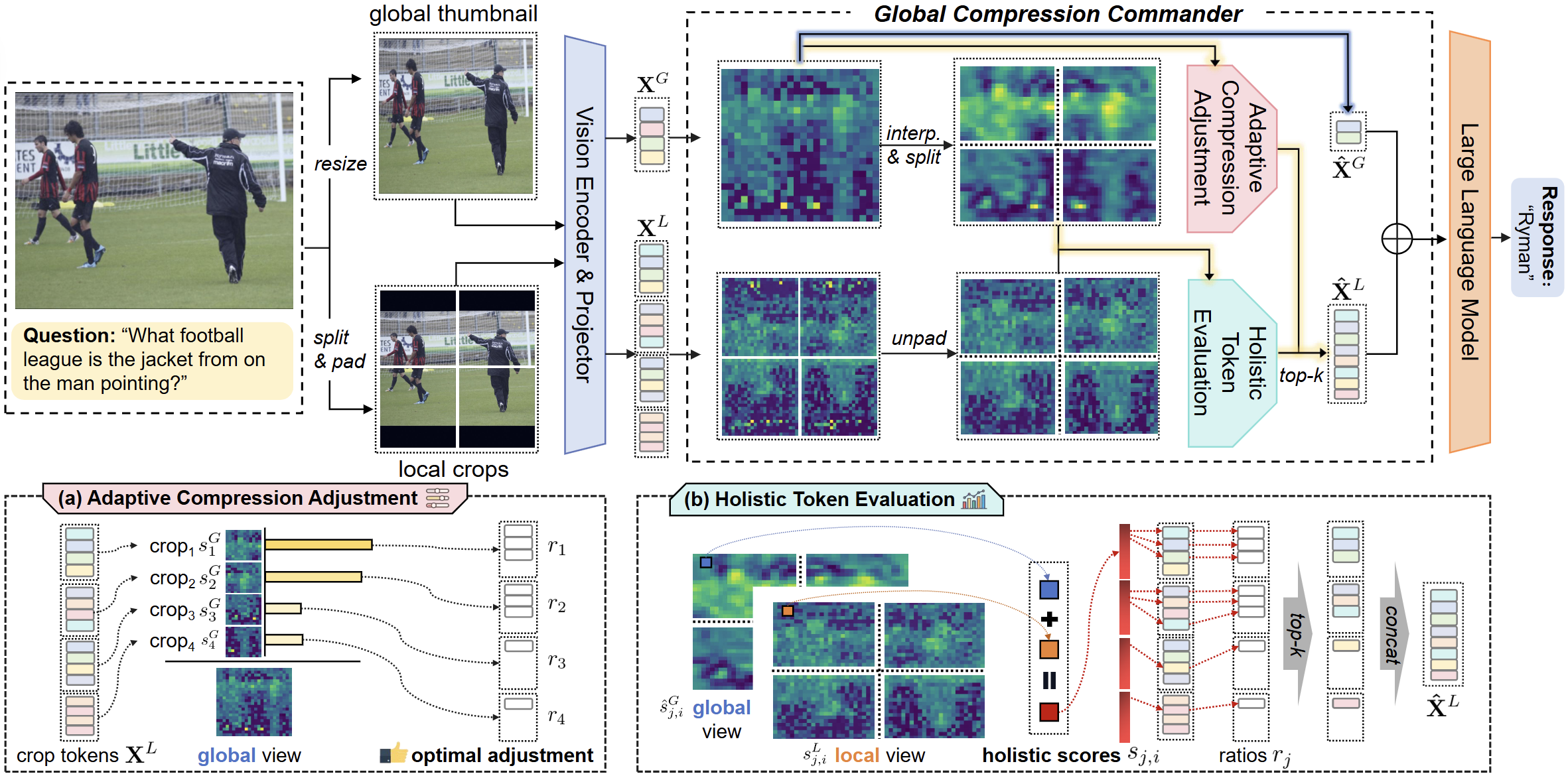
Xuyang Liu, Ziming Wang, Junjie Chen, Yuhang Han, Yingyao Wang, Jiale Yuan, Jun Song, Siteng Huang, Honggang Chen
- Model Capability: LLaVA-NeXT, LLaVA-OV.
- Token Compression: Only 10% tokens, 90%+ on 10 tasks.
- High Efficiency: FLOPs 9.1%, memory 60%, 1.8× throughput.
Conference Papers
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, and 10 more authors, "OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models". In International Conference on Machine Learning (ICML), 2026. [paper] [code] [huggingface paper] [量子位]

Peize He, Yaodi Luo, Xiaoqian Liu, Xuyang Liu, Jiahang Deng, Yaosong Du, Bangyu Li, Xiyan Gui, Yuxuan Chen, Linfeng Zhang, "HeadRouter: Dynamic Head-Weight Routing for Task-Adaptive Audio Token Pruning in Large Audio Language Models". In Proceedings of the ACM International Conference on Multimedia (MM), 2026. [paper] [page]
Yuxuan Wang, Peize He, Xiyan Gui, Xiaoqian Liu, Junhao He, Xuyang Liu, Zichen Wen, Xuming Hu, Linfeng Zhang, "AudioKV: KV Cache Eviction in Efficient Large Audio Language Models". In Proceedings of the ACM International Conference on Multimedia (MM), 2026. [paper]
Yuhang Han, Yuyang Wu, Zhengbo Jiao, Yiyu Wang, Xuyang Liu, Shaobo Wang, Hanlin Xu, Xuming Hu, Linfeng Zhang, "Bridging Visual Representation and Reinforcement Learning from Verifiable Rewards in Large Vision-Language Models". In Proceedings of the European Conference on Computer Vision (ECCV), 2026. [paper] [page]
Yiyu Wang*, Xuyang Liu*,†, Xiyan Gui, Xinying Lin, Boxue Yang, Chenfei Liao, Tailai Chen, Linfeng Zhang, "Accelerating Streaming Video Large Language Models via Hierarchical Token Compression". In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [paper] [code] [Xiaohongshu] [PaperWeekly]

Junjie Chen*, Xuyang Liu*,†, Zichen Wen, Yiyu Wang, Siteng Huang, Honggang Chen, "Variation-aware Vision Token Dropping for Faster Large Vision-Language Models". In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [paper] [code] [机器之心]

Minhao Xiong, Zichen Wen, Zhuangcheng Gu, Xuyang Liu, Rui Zhang, Hengrui Kang, Jiabing Yang, Junyuan Zhang, Weijia Li, Conghui He, Yafei Wang, Linfeng Zhang, "Prune2Drive: A Plug-and-Play Framework for Accelerating Vision-Language Models in Autonomous Driving". In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [paper] [code]
Junlong Ke, Zichen Wen, Boxue Yang, Yantai Yang, Xuyang Liu, Chenfei Liao, Zhaorun Chen, Shaobo Wang, Linfeng Zhang, "Flash-Unified: A Training-Free and Task-Aware Acceleration Framework for Native Unified Models". In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Findings, 2026. [paper] [code]
Xuyang Liu*, Xiyan Gui*, Yuchao Zhang, Linfeng Zhang, "Mixing Importance with Diversity: Joint Optimization for KV Cache Compression in Large Vision-Language Models". In International Conference on Learning Representations (ICLR), 2026. [paper] [code] [page] [Xiaohongshu] [量子位]

Zichen Wen, Jiashu Qu, Dongrui Liu, Zhiyuan Liu, Ruixi Wu, Yicun Yang, Xiangqi Jin, Haoyun Xu, Xuyang Liu, Weijia Li, Chaochao Lu, Jing Shao, Conghui He, Linfeng Zhang, "The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs". In International Conference on Learning Representations (ICLR), 2026. [paper] [code] [huggingface paper] [量子位]

Xuyang Liu, Ziming Wang, Junjie Chen, Yuhang Han, Yingyao Wang, Jiale Yuan, Jun Song, Siteng Huang, Honggang Chen, "Global Compression Commander: Plug-and-Play Inference Acceleration for High-Resolution Large Vision-Language Models". In Proceedings of the 40th AAAI Conference on Artificial Intelligence, 2026. [paper] [code] [poster]

Yuhang Han*, Xuyang Liu*, Zihan Zhang, Pengxiang Ding, Junjie Chen, Donglin Wang, Honggang Chen, Qingsen Yan, Siteng Huang, "Filter, Correlate, Compress: Training-Free Token Reduction for MLLM Acceleration". In Proceedings of the 40th AAAI Conference on Artificial Intelligence, 2026. [paper] [page] [code][poster]

Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, Yueting Zhuang, "GUI-G2: Gaussian Reward Modeling for GUI Grounding". In Proceedings of the 40th AAAI Conference on Artificial Intelligence, 2026. [paper] [code] [huggingface paper] [page] [机器之心]

Xuyang Liu*, Yiyu Wang*, Junpeng Ma, Linfeng Zhang, "Video Compression Commander: Plug-and-Play Inference Acceleration for Video Large Language Models". In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025. [paper] [code] [page] [Xiaohongshu] [机器之心] [PaperWeekly] [slides] [poster] [video]

Chang Zou*, Xuyang Liu*, Ting Liu, Siteng Huang, Linfeng Zhang, "Accelerating Diffusion Transformers with Token-wise Feature Caching". In International Conference on Learning Representations (ICLR), 2025. [paper] [page] [code] [量子位] [poster]

Shaobo Wang, Hongxuan Tang, Mingyang Wang, Hongrui Zhang, Xuyang Liu, Weiya Li, Xuming Hu, Linfeng Zhang, "Gnothi Seauton: Empowering Faithful Self-Interpretability in Black-Box Transformers". In International Conference on Learning Representations (ICLR), 2025. [paper] [code]
Yi Xin*, Siqi Luo*, Xuyang Liu*, Yuntao Du*, Haodi Zhou, Xinyu Cheng, Christina Lee, and 10 more authors, "V-PETL Bench: A Unified Visual Parameter-Efficient Transfer Learning Benchmark". In Neural Information Processing Systems Datasets and Benchmarks Track (NeurlPS D&B Track), 2024. [paper][page] [code] [poster]
Journal Papers
Xuyang Liu*, Ting Liu*, Siteng Huang, Yi Xin, Yue Hu, Quanjun Yin, Donglin Wang, Yuanyuan Wu, Honggang Chen, "M2IST: Multi-Modal Interactive Side-Tuning for Efficient Referring Expression Comprehension". IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025. [paper] [code]
Preprints & Under Submission
Yuzhe Chen, Jiale Cao, Xuyang Liu, Jin Xie, Aiping Yang, Yanwei Pang, "STDec: Spatio-Temporal Stability Guided Decoding for dLLMs". arXiv preprint arXiv:2604.06330. [paper] [page]
Xinying Lin, Xuyang Liu†, Yiyu Wang, Teng Ma, Wenqi Ren, "V-CAST: Video Curvature-Aware Spatio-Temporal Pruning for Efficient Video Large Language Models". arXiv preprint arXiv:2603.27650. [paper] [code] [page]
Xuyang Liu*, Zichen Wen*, Shaobo Wang*, Junjie Chen, Zhishan Tao, and 10 more authors, "Shifting AI Efficiency From Model-Centric to Data-Centric Compression". arXiv preprint arXiv:2505.19147. [paper] [project] [huggingface paper] [Twitter@Rohan Paul]

Ting Liu*, Xuyang Liu*, Liangtao Shi, Zunnan Xu, Yue Hu, Siteng Huang, Yi Xin, Bineng Zhong, Donglin Wang, "Sparse-Tuning: Adapting Vision Transformers with Efficient Fine-tuning and Inference". arXiv preprint arXiv:2405.14700. [paper] [code]

Thesis
Xuyang Liu, "Research on Efficient Training and Inference Methods for Vision-Language Understanding". Master’s thesis, Sichuan University, 2026. (Outstanding Master’s Thesis, top 2%).
🤗 Resources
Please find my full repositories on my GitHub profile. 
Awesome Generation Acceleration 
- Duty: Owner.
- Description: An open-source repository that curates a collection of recent awesome papers on AIGC acceleration.
Awesome Token-level Model Compression 
- Duty: Owner.
- Description: An open-source repository that curates a collection of recent awesome papers on token-level model compression.
💻 Experiences
Internships
Jul 2025 - Present
Research Intern - OPPO Research Institute, OPPO, Shenzhen
- Thesis: Video Understanding with Large Vision-Language Models.
- Supervisor: Prof. Lei Zhang.
Apr 2025 - Jul 2025
Research Intern - Venus Team, Ant Group, Hangzhou
- Thesis: Multi-modal Graphical User Interface (GUI) Agents.
Jul 2024 - Mar 2025
Research Intern - Future Living Lab, Alibaba Group, Beijing
- Thesis: Efficient Multi-modal Large Language Models.
Visiting
June 2024 - Present
Research Assistant - EPIC Lab, Shanghai Jiao Tong University, Remote
- Thesis: Efficient Multi-modal Large Language Models.
- Supervisor: Prof. Linfeng Zhang.
Mar 2023 - Sep 2023
Visiting Student - MiLab, Westlake University, Hangzhou
- Thesis: Efficient Transfer of Vision-language Models.
- Supervisors: Dr. Siteng Huang and Prof. Donglin Wang.
📠 Services
Conference Reviewer
- International Conference on Learning Representations (ICLR)
- International Conference on Machine Learning (ICML)
- Advances in Neural Information Processing Systems (NeurIPS)
- AAAI Conference on Artificial Intelligence (AAAI)
- ACM International Conference on Multimedia (MM)